









PRESTATAIRE DE SERVICE.
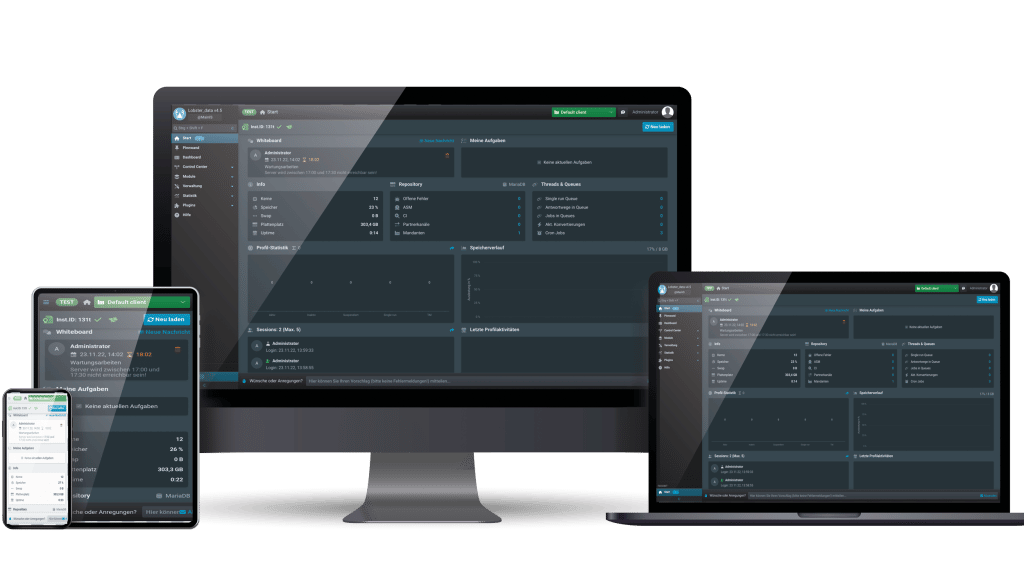
HAUTE PERFORMANCE AVEC LOBSTER_DATA.
L’architecture moderne et l’utilisation du langage Java font de Lobster_data une application hautement performante offrant de nombreux avantages. Grâce à son approche innovante, Lobster sépare le traitement et la communication des paquets de données et assure ainsi une transmission sécurisée.

ILS NOUS FONT CONFIANCE







Avantages.
Lobster mise sur une informatique plus durable et minimise l’empreinte écologique du traitement de vos données. En privilégiant une transmission par paquets, nous évitons les files d’attente et assurons une gestion fluide de toutes les transactions. Cela réduit non seulement la latence et le temps de traitement, mais aussi les coûts des transmissions les plus volumineuses grâce à la compression et à l’automatisation.

Multi-threading
Lobster_data prend en charge le multi-threading, ce qui permet à la fois l’exécution simultanée de plusieurs threads dans un programme et (grâce à l’utilisation de plusieurs cœurs de CPU) une amélioration significative des performances.

Stockage efficace
Lobster_data dispose d’une gestion automatique et efficace du stockage grâce à la fonction Garbage-Collection, ce qui réduit considérablement le risque de fuites de mémoire et de crashs.

Compilation en flux tendu.
La compilation en flux tendu dans Lobster_data améliore les performances en permettant à la machine virtuelle Java (JVM) de compiler dynamiquement le bytecode en code machine natif au moment de l’exécution.

Indépendance de la plateforme
En tant que logiciel basé sur Java, Lobster_data peut être exécuté sur toute plateforme sur laquelle une machine virtuelle Java (JVM) est installée.
Des milliers de requêtes AS400 peuvent être traitées en quelques minutes au lieu de quelques heures !
x Masquer
COMPOSANTS & VUE D'ENSEMBLE DES FONCTIONNALITÉS
Etablissement direct de connexions TCP dans le cas où les terminaux et les machines à connecter ne sont pas compatibles MQTT et/ou OPC UA.
Optimisation des processus
Le module Lobster_data pour l'optimisation des processus (PLO) permet un traitement optimisé même en cas de volume de processus important.

Module de transmission asynchrone
Notre module complémentaire ASM permet la transmission de nombreux fichiers à vos partenaires de communication à un moment défini au préalable. L'utilisation du streaming XML permet un traitement extrêmement rapide des fichiers XML, même volumineux (de l'ordre de plusieurs Go), avec un besoin minimal de stockage. Ulrich Peekhaus Lobster_data bietet neben der Server-Hardware Aufrüstung weitere Tipps und Tricks zur Verbesserung der Gesamtperformance. Im Betrieb können durch Performance-Analysen gezielte Optimierungen anhand von statistischen Daten vorgenommen werden. Lobster_data gibt dezidierte Hinweise für Optimierungen durch Auslastungs-Monitoring und die Auflistung der APIs mit den meisten Konvertierungen, Fehlern, Datenvolumen und längsten Verarbeitungszeiten. Bei Lobster fungiert der Node Controller als interner Lastverteiler und bietet mehrere Leistungsvorteile: Die Verteilung des eingehenden Datenverkehrs auf mehrere Working Nodes stellt sicher, dass bei Ausfall eines Nodes der Traffic auf einen anderen verfügbaren Node umgeleitet wird. Sollte der Node Controller ausfallen, übernimmt automatisch der nächste Working Node dessen Aufgabe. Wartungsarbeiten oder Updates können pro Node sukzessive vorgenommen werden, so dass für das Gesamtsystem keine Downtime entsteht. Load Balancing verkürzt die Antwortzeiten dadurch, dass die Verbindungen nur an solche Nodes gegeben werden, die weniger ausgelastet oder für spezielle Aufgaben optimiert sind. Der Lastverteiler bewältigt mehr Daten-Traffic und API-Anfragen, indem er die Last auf mehrere Nodes verteilt und so eine bessere Skalierbarkeit und Kapazitätsplanung ermöglicht. Nimmt der Daten-Traffic zu, können zusätzliche Nodes zur Last-Bewältigung in den Pool aufgenommen werden. Der Lastverteiler stellt eine optimale Auslastung aller Nodes im Pool sicher. Er minimiert die Über- oder Unterauslastung von Ressourcen und verbessert die Gesamteffizienz des Systems. Die Abkürzungen ETL (Extract, Transform, Load) und ELT (Extract, Load, Transform) bezeichenen Datenintegrationsprozesse, um Daten aus einem oder mehreren Quellsystemen in ein Zielsystem zu verschieben und zu transformieren. Das ETL/ELT-Modul in Lobster_data unterstützt bei der Zusammenführung und Verarbeitung großer Datenmengen aus verschiedenen Datenquellen. Über sehr schnelle ETL/ELT-Prozesse können Daten in eine Ziel-Datenbank (Data Warehouse, Data Lake) geladen werden. Mit dem ETL/ELT-Modul in Lobster_data erfolgt zusätzlich die hochperformante Abarbeitung aller Datenbereinigungs- und Transformationsregeln und damit eine schnelle Verfügbarkeit der Daten im Zielsystem. Bestehende Schnittstellen zu Datenbanken, ERP-, Logistik- oder Shop-Systemen können mit nur wenig Aufwand für die Umsetzung von ETL/ELT herangezogen werden. Das Lobster ETL/ELT-Modul bietet eine leistungsfähige DWH-Vorverarbeitung von Massendaten für Dateien mit einer Größe von bis zu 6 GB. Die für die Datenintegration und Daten-Bereitstellung im Rahmen von Business Intelligence benötigte Zeit verkürzt sich damit erheblich. Lobster_data ist hochperformant. Als Beispiel: Bei 2TB Datenvolumen und 22 Millionen Daten-Requests ergibt sich bei einem Server mit 16 Kernen und 48 GB Hauptspeicher zumeist eine Auslastung von nur 30%. Dennoch besteht für sehr große Datenvolumen die Möglichkeit einer zusätzlichen Verteilung, sodass der zentrale Node Controller den eingehenden Datenverkehr auf einen oder mehrere Working Nodes in verschiedenen Systemen aufteilt und eine Überlastung des einzelnen Systems verhindert. Wird eine Anfrage an einen Node Controller gesendet, verwendet dieser vordefinierte Einstellungen, um festzulegen, welcher Working Node im Cluster die Anfrage bearbeiten soll. Sobald ein Node ausgewählt wurde, leitet das Lastausgleichsystem die Anfrage direkt an diesen Node weiter.
5 rue du Helder
5 rue du Helder
5 rue du Helder
E: support@lobster.de (07:00 - 17:00)
E: support.pro@lobster.de (08:00 - 18:00)
E: support.pim@lobster.de (08:00 - 17:00)
XML-Streaming
![]()
Il nous suffit d'appuyer sur un seul bouton pour accéder aux formats dont nous avons besoin. Ce qui prenait auparavant plusieurs jours, nous le faisons maintenant en quelques heures avec Lobster_data.
Responsable informatique, Knipex![]()
![]()



Tipps & Tricks
Hardware
Performance-Analyse
Lastverteilung
Verbesserte Verfügbarkeit und Betriebszeit
Schnellere Antwortzeiten
Skalierbarkeit
Verbesserte Ressourcen-nutzung
ETL/ELT
Use Case
NOS ACTUALITÉS.
75009 Paris
T: +33 1 74 54 66 27
F: +33 1 74 54 66 27
E: info@lobster-france.com
75009 Paris
T: +33 1 74 54 66 27
F: +33 1 74 54 66 27
E: info@lobster-france.com
75009 Paris
T: +33 1 74 54 66 27
F: +33 1 74 54 66 27
E: info@lobster-france.com
T: +49 8158 4529 350 (08:00 - 16:00)
T: +49 8158 4529 555 (09:00 - 17:00)
T: +49 8158 4529 395 -20 (09:00 - 16:00)![]()
Zur Live-Demo.
Lernen Sie LOBSTER_data kostenlos kennen. Anmelden und Loslegen.
Oder rufen Sie uns an:

DARUM ZU LOBSTER.
NOUS SOMMES LÀ POUR ÇA.
![]()
Demander une démonstration live
En savoir plus sur Lobster_data. Inscrivez-vous et lancez-vous.
Ou appelez-nous
![]()
Demander une démonstration live
En savoir plus sur Lobster_data. Inscrivez-vous et lancez-vous.
Ou appelez-nous