XML-Parser V4
Vorteile von V4
Der XML-V4-Parser (Zusatzmodul) bietet signifikanten Performance-Gewinn bei extrem geringem Speicherverbrauch. Gegenüber dem XML-V3-Parser sinkt der Speicherbedarf etwa auf 10%. Bei Eingangsdateien bis etwa 100 MB sinkt die Laufzeit auf ca. 5% gegenüber Version 3. Weitere deutliche Performance-Gewinne sind über optionale XPath-Filter möglich.
Außerdem können extrem große XML-Eingangsdaten bis maximal 250 GB geparst werden. Allerdings verlängern sich dann die Laufzeiten wegen der nötigen Plattenzugriffe wieder deutlich.
Des Weiteren können die Daten aus der XML-Eingangsdatei beim Parsen in virtuellen Elementen (Chunks) zusammengefasst werden. In diese Chunks können auch Daten außerhalb des Parsing-Bereichs eingefügt werden.
Preparser
Wenn ein Preparser zusammen mit dem XML-V4-Parser verwendet wird, muss die Backupdatei mit dem Ergebnis des Preparsers überschrieben werden.
Einstellungen
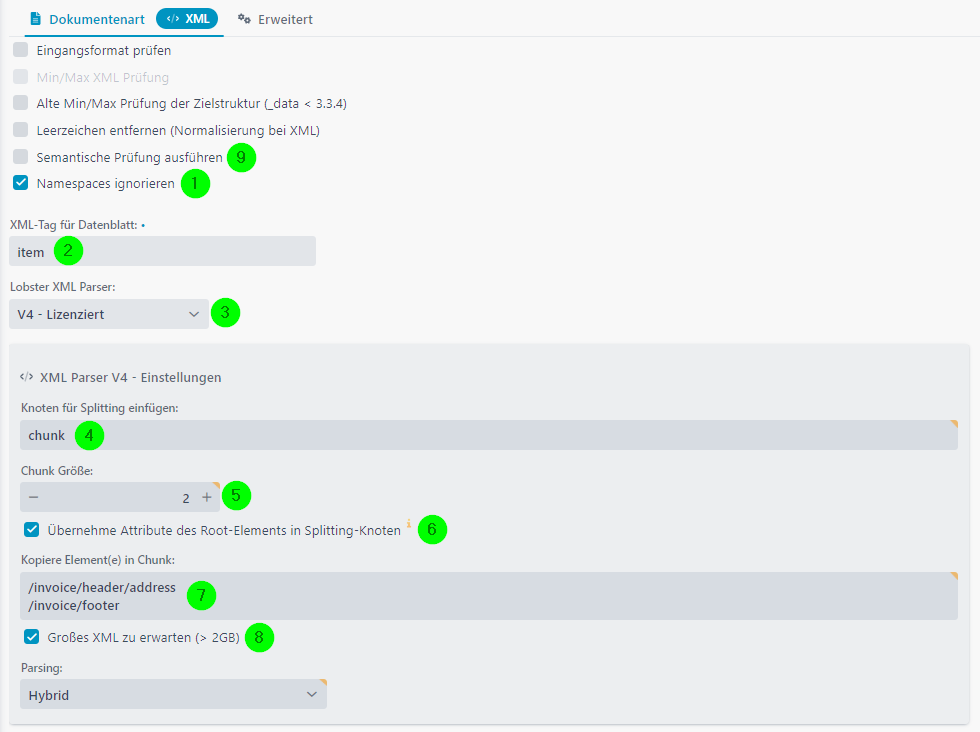
(1) Muss gesetzt sein bei V4.
(2) Gibt den Tag-Namen (Element) an, unterhalb dessen geparst werden soll. Hier muss ein Eintrag vorgenommen werden, auch wenn die ganze XML-Struktur geparst werden soll. Ein zu parsendes Teildokument muss ebenfalls der XML-Konvention entsprechen (wohlgeformt). Hinweis: Kann auch ein XPath-1.0-Ausdruck sein, wie z. B. /inventory/books[@title="xxxx"]. Hinweis: Siehe auch Abschnitt Auswirkung eines Eintrags im Feld "XML-Tag für Datenblatt".
(3) Muss auf V4 gesetzt sein.
(4) Wir wollen nicht pro item ein neues Datenblatt erzeugen, sondern 2 item-Elemente, siehe (5), in ein Datenblatt packen. Deswegen erzeugen wir ein neues, künstliches Root-Element chunk. Siehe Abschnitt Bildung von Chunks unten.
(5) Anzahl der item-Elemente pro Datenblatt, also pro chunk, siehe (4). Siehe Abschnitt Bildung von Chunks unten.
(6) Wir haben zwei Attribute date und ref im Root-Element invoice. Diese benötigen wir im Mapping, deswegen aktivieren wir diese Checkbox und alle verfügbaren Attribute werden in chunk (4) kopiert.
(7) Die angegebenen Elemente einschließlich ihrer Kind-Elemente werden in jedes chunk-Element (4) übernommen. Alle XPath-1.0-Ausdrücke sind erlaubt. Siehe Abschnitt Attribute und Elemente in jedes Datenblatt redundant kopieren unten.
(8) Ist die XML-Datei kleiner als 2 GB, deaktivieren Sie diese Checkbox bitte, ansonsten setzen. Wird automatisch gesetzt , wenn die Datei größer 2 GB ist, verwendet dann aber die konservative Parsing-Methode Disk .
|
In Memory |
Sie haben genügend Arbeitsspeicher (RAM) - alles wird im RAM ausgeführt. |
|
Disk |
Nur ein Teilbereich der XML-Datei wird in den Speicher geladen. Dies funktioniert intern ähnlich wie ein Cursor-Select bei Datenbanken - das System "geht" intern nach vorne oder hinten, um die Daten für das Mapping zu holen. |
|
Hybrid |
Beste "Wahl der Waffen". Das Parsen erfolgt im Modus Disk, erzeugte Datenblätter werden aber im Speicher bearbeitet. Reduziert die Festplattenzugriffe und erhöht somit die Verarbeitungsgeschwindigkeit. |
(9) Eingehende Dateien können mit semantischen Regeln überprüft werden. Siehe Abschnitt Semantische Prüfung.
Beispiel
Es wird folgende XML-Datei verwendet: test.xml
<?xml version="1.0" encoding="ISO-8859-1"?><invoice date="07.03.13" ref="R-0001"> <header> <customer>Lobster</customer> <address> <name>Lobster GmbH</name> <street>Münchner Str. 15a</street> <zip>82319</zip> <city>Starnberg</city> </address> </header> <positions> <item type="1" desc="billing"> <pos>1</pos> <article id="A-001" name="Artikel 1" price="1050" amount="1" /> <note>Vorsicht - Glas!</note> </item> <item type="0" desc="return"> <pos>2</pos> <article id="A-002" name="Artikel 2" price="920" amount="2" /> </item> <item type="1" desc="billing"> <pos>3</pos> <article id="A-003" name="Artikel 3" price="90" amount="3" /> <note>Siehe Zählerstand</note> </item> </positions> <footer> <note code="001">Vollständig</note> </footer></invoice>Wenn wiederholte Subelemente (hier item) zu mehreren Datenblättern führen sollen, wird unter (2) nicht das reale Root-Element (invoice) des XML-Dokuments angegeben (siehe Abschnitt Auswirkung eines Eintrags im Feld "XML-Tag für Datenblatt"). Bei vorherigen Parsern (vor V4) gingen nun alle Attribute des Root-Elements und alle Eltern- oder Geschwister-Elemente, die nicht innerhalb des Elements item sind, verloren. Mit dem XML-Parser V4 können Daten aus diesen "blinden" Bereichen des XML-Dokuments in jedes Datenblatt kopiert werden, wie unten in Abschnitt Attribute und Elemente in jedes Datenblatt redundant kopieren beschrieben wird.
Bildung von Chunks
Falls die Quelldaten so aufgebaut sind, dass sehr viele kleine Datenblätter entstehen würden, weil z. B. mehrere Millionen item-Elemente vorkommen, kann die Performance dadurch ungünstig werden. In diesem Fall bietet es sich an, mehrere item-Elemente zu einem Datenblatt zusammen zu fassen. Diese Einheit von mehreren item-Elementen ist aber in dem originalen XML nicht als Struktur vorhanden. Sie kann vom Parser als virtuelles Element (hier chunk) erzeugt werden, indem man in (4) einen Namen für das virtuelle Element einträgt. Dieses "Chunk"-Element erscheint dann als Root-Element, in dem mehrere item-Elemente enthalten sind.
Die Bildung von Chunks mit (4) und (5) ist optional. Wenn (4) leer bleibt, wird pro (2) ein Datenblatt erzeugt (im Beispiel pro item). Dann sollte der oberste Knoten der Quellstruktur dem item-Element entsprechen.
Wenn in (4) ein virtuelles Chunk-Element benannt wird, muss in der Profil-Quellstruktur ein zusätzlicher Root-Knoten eingesetzt werden, der dem Chunk-Element (hier chunk) entspricht. Dieser Knoten erhält die Satzarterkennung wie (4), um das virtuelle Chunk-Element parsen zu können (also Ist gleich=chunk). Und hier die passende Quellstruktur als Screenshot. Satzarterkennungen sind wie gewohnt zu definieren, werden bei einem automatischen Erzeugen der Quellstruktur aber natürlich bereits angelegt. Verwenden Sie dazu die Datei for_structure.xml. Und hier das komplette Profil: Profile-XML_V4.pak

Attribute und Elemente in jedes Datenblatt redundant kopieren
Nehmen wir an, dass wir für unsere Quelldatei, wie oben, als XML Tag für Datenblatt das Element item verwenden. Dann sind die Attribute des Elements invoice und alle Daten im Element header außerhalb des geparsten Bereichs. Ab XML Parser V4 können die Attribute des realen Root-Elements in jedes erzeugte Datenblatt übernommen werden, siehe Checkbox (6). Analog dazu kann man unter (7) jene Elemente eintragen, die real außerhalb item liegen, die aber in jedes Datenblatt übernommen werden sollen. Die erforderliche Anpassung der Profil-Quellstruktur muss gegenwärtig von Hand vorgenommen werden (bereits getan in unserer Besipiel-Struktur).
Internes XML auf Basis der vorherigen Einstellungen
Durch unsere Einstellungen sieht das Eingangs-XML intern wie folgt aus.
Datenblatt 1
<?xml version="1.0" encoding="ISO-8859-1"?><chunk date="07.03.13" ref="R-0001"> <address> <name>Lobster GmbH</name> <street>Münchner Str. 15a</street> <zip>82319</zip> <city>Starnberg</city> </address> <item type="1" desc="billing"> <pos>1</pos> <article id="A-001" name="Artikel 1" price="1050" amount="1" /> <note>Vorsicht - Glas!</note> </item> <item type="0" desc="return"> <pos>2</pos> <article id="A-002" name="Artikel 2" price="920" amount="2" /> </item> <footer> <note code="001">Vollständig</note> </footer></chunk>Datenblatt 2
<?xml version="1.0" encoding="ISO-8859-1"?><chunk date="07.03.13" ref="R-0001"> <address> <name>Lobster GmbH</name> <street>Münchner Str. 15a</street> <zip>82319</zip> <city>Starnberg</city> </address> <item type="1" desc="billing"> <pos>3</pos> <article id="A-003" name="Artikel 3" price="90" amount="3" /> <note>Siehe Zählerstand</note> </item> <footer> <note code="001">Vollständig</note> </footer></chunk>