Nicht mehr als nötig
Nicht immer sind tatsächlich alle Daten relevant, die in ein Profil hineinlaufen. Wenn Sie hier schon die Strukturen auf das Wesentliche beschränken, können Sie einiges an Speicher und Geschwindigkeit sparen. Manchmal ist es sogar möglich die Eingangsdaten komplett zu ignorieren.
Die Datei anhand weniger Daten durchschleusen
Nehmen wir folgenden Fall an. Sie bekommen verschiedene EDIFACT-Dokumente, die Sie eigentlich nur "wie empfangen" irgendwo hin weiterleiten wollen, z. B. in Verzeichnissen ablegen. Allerdings sollen die Dateien je nach Absender in unterschiedlichen Verzeichnissen landen.
Der Absender lässt sich ja normalerweise an den Kanälen festmachen, über die die Daten hereinkommen. Was aber, wenn die Dateien alle nur in einem einzigen Verzeichnis liegen, das Sie regelmäßig absuchen, und sich am Dateinamen nicht festmachen lässt, von wem sie ursprünglich kommen? Der Absender, also der Datenersteller, ist im UNB-Segment festgehalten.
UNB+UNOB:2+Absender+Empfaenger+....Der Empfänger sind im Beispiel immer Sie, es können aber Dateien von Partner1 und Partner2 kommen.
UNB+UNOB:2+Partner1+Sie+...UNB+UNOB:2+Partner2+Sie+...Natürlich können Sie jetzt ein 1:1-Mapping mit den entsprechenden EDIFACT-Vorlagen machen und dort das entsprechende Feld abprüfen. Das ist bei EDIFACT-Dateien nicht die Welt, da hier nicht mit großen Daten zu rechnen ist. Aber trotzdem, man kann es auch effektiver (und dabei auch schneller) machen. Also legen wir ein Profil an, das die Daten wie CSV behandelt, und zwar mit dem Datensatz-Trennzeichen ', das in EDIFACT-Dateien normalerweise der Segmenttrenner ist.

Angenommen, die Datei fängt wie folgt an.
UNA:+.? 'UNB+UNOA:2+Partner1+Sie+040820:0006+3689'UNH+....Dann ist die erste Zeile das UNA-Segment, die zweite das UNB-Segment, usw. Wenn die EDIFACT-Datei als Einzeiler oder im 80-Zeichen-Blocksatz daherkommt, ist damit schon alles in Butter. Es wird ja immer nach ' aufgeteilt. Und Sender und Empfänger sollten immer noch unter den ersten 80 Zeichen sein. Ein Zeilenumbruch wird uns also so oder so nicht dazwischenfunken. Sollte die Datei aber schön lesbar jedes Segment in einer eigenen Zeile beinhalten, müssen wir für unser Routing-Profil noch eine kleine Vorarbeit leisten. Wir müssen die Zeilenumbrüche eliminieren. Dazu setzen Sie den Preparser EncodingPatcher ein. Und zwar mit einer Konfigurationsdatei folgenden Inhalts.
0x0A=0x0D=Das sagt ihm, dass er die beiden Zeichen, die bei Windows (0x0D0A) und Linux/Unix (0x0A) die Zeilenumbrüche darstellen, einfach durch nichts ersetzen, also löschen soll. Schon wird aus dem Dokument ein Einzeiler. Die Struktur dazu sieht wie folgt aus, wobei der Knoten nur das UNB-Segment aufnehmen soll.

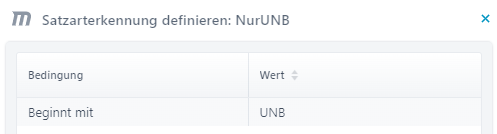
Das Trennzeichen Spalte/Datensatz auf dem Knoten NurUNB lassen Sie leer, dann wird das ganze Segment in das Feld Inhalt geschrieben. Als Satzarterkennung verwenden Sie Beginnt mit und UNB. Bei diesem Mapping kommt folgendes raus.

Nun können Sie im Zielfeld mittels Funktion überprüfen, ob das UNB-Segment die Zeichenkette Partner1 oder Partner2 enthält und durch Variablen den jeweils passenden Antwortweg nutzen.
Entsprechende Methoden funktionieren natürlich auch bei anderen Formaten. Nur bei XML sollten Sie einfach die Quellstruktur auf das Wesentliche beschränken, aber trotzdem den XML-Parser verwenden. Zum Beispiel bei folgenden Daten.
<Auftrag><Absender><Kundennummer>123</Kundennummer><Nachname>Meier</Nachname>...</Absender><Empfaenger><Firmennummer>987</Firmennummer>...</Empfänger><Positionen><Position><!-- viele viele Felder></Position>...</Positionen></Auftrag>Wenn Sie tatsächlich den ganzen Auftrag verarbeiten wollen, müssen Sie natürlich die ganze Struktur aufspannen. Wenn Sie aber nur je nach Absender (erkennbar an seiner Kundennummer) die Daten irgendwo hin weitergeben wollen, halten Sie die Struktur so klein wie möglich.
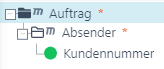
Das reicht. Den Rest der Daten brauchen Sie ja nicht. Also warum erst umständlich alles einlesen? Und ganz wichtig: Nehmen Sie den XML-Parser V3 oder V4, sonst wird ganz sinnlos doch erst mal alles eingelesen.
Hinweis: Wenn Sie sich nicht sicher sind, ob Sie bestimmte Knoten in Ihrer Struktur nicht vielleicht doch später noch brauchen, können Sie diese auf "inaktiv" setzen. Dann werden Sie weder beim Parsen noch beim Mappen berücksichtigt, stehen aber für den Fall der Fälle doch noch zur Verfügung um wieder aktiviert zu werden.
Die Methode, einen von mehreren Antwortwegen per Variable auszuwählen, ist übrigens nicht die einzige Möglichkeit datenabhängig verschiedene Ziele anzusteuern. Eine andere finden Sie im Abschnitt Zusatzkennungen (zentral) beschrieben.
Nur ein Teil der Daten interessiert mich
Die eintreffenden Daten sind viel umfangreicher als das, was Sie auswerten wollen. Also warum alles einlesen, dabei intern einen Haufen Speicher verbrauchen, und danach womöglich 90% wieder ungenutzt wegwerfen?
Bei EDIFACT-Dateien kommen sie außer in extrem einfachen Fällen wie im vorigen Kapitel zum Durchschleusen leider nicht um das Einlesen der kompletten Daten herum. Die Struktur ist einfach zu sehr davon abhängig, dass alle Segmente korrekt eingelesen werden. Bei X12 ebenfalls. Aber da die Daten im Normalfall nicht allzu umfangreich sind, ist das auch nicht weiter schlimm.
XML-Daten können schon recht umfangreich sein. Aber hier hilft ebenfalls die Methode, die im vorigen Kapitel beschrieben wurde.
CSV (DB, Excel) und Feste Länge (SAP IDoc): Auch hier können Sie die Struktur auf die Knoten beschränken, die auf die tatsächlich interessanten Datensätze anspringen.
Bedenken Sie aber, dass z. B. Knoten, die z. B. ein neues Datenblatt erzeugen, strukturell wichtig sind und daher nicht entfernt werden dürfen. Und natürlich dürfen Felder nicht einfach "mittendrin" weggelassen werden wie im folgenden Fall (CSV).
POS,4711,"Broschüre Lobster_data",5,PDF,....Nach der Kennung POS folgt die Artikelnummer 4711, dann der Artikelname, die Menge, das Format und danach irgendwas anderes. Sie interessiert nur die Artikelnummer und die Menge. Der Knoten im Baum muss natürlich mindestens vier Felder enthalten, damit alles bis zur Menge korrekt eingelesen werden kann. Erst den Rest dürfen Sie ignorieren.
Der Inhalt interessiert mich gar nicht (oder ist binär)
Meist ein Spezialfall des Duchschleuse-Themas. Sie bekommen z. B. Bilder (GIF, TIFF, ...) und möchten nur anhand des Dateinamens entscheiden, wo Sie die Daten (wie empfangen) ablegen. In dem Fall können Sie die Dateien selbst ja gar nicht parsen. Aber ein Mapping ist notwendig um Variablen (true/false) für verschiedene Antwortwege zu setzen oder bestimmte Kanäle der Partnerverwaltung auzuwählen. Den Dateinamen haben Sie ja dann in der System-Variable VAR_FILENAME. Sie brauchen nur irgendein Zielfeld um die Funktionen darauf aufzusetzen.
Hier hilft Ihnen ein Preparser weiter, der immer denselben Text liefert: Der DummyPreParser. Er braucht keinerlei Konfiguration und liefert immer dasselbe zurück: Den Text dummy data im Encoding 8859_1. Hinweis: Verwenden Sie einfach die Checkbox Daten-Routing.
Ein simples CSV-Mapping mit einem einzigen Feld, ein Zielfeld, das die Variablen setzt und fertig. Sie sparen Lobster_data eine Menge unnötige Arbeit.